
Man Versus Machine: Improving NLP Analysis in Finance

- By Sam van de Schootbrugge
- Sign-up to discuss on Slack
- 7 min read
Natural language processing (NLP) is a machine learning method that is increasingly being applied to financial market research. Nested in econometrics, NLP unlocks textual data that can be used to predict changes in more traditional variables, like stock returns. Typically, it involves creating sentiment scores from general-purpose dictionaries in which humans have assigned words positive or negative values depending on their meaning.
This is not the case in a new Journal of Financial Economics paper. The authors develop dictionaries in which words are assigned values by an algorithm, not a person. Frequently occurring words in earnings calls that typically boost a firm’s subsequent stock price are given positive values, while those that hurt a firm’s price get negative values.
Tallying up positive versus negative values in each document gives an algo-generated sentiment index that, according to the authors, is better at predicting stock price action than a human-generated one.
Specifically, the paper’s dictionaries are shown to be at least twice as good at explaining stock price movements around earnings calls as the popular Loughran and McDonald (LM) method. Their methodology is also able to capture more nuanced aspects of the English language (through bigrams), avoids over-fitting, and, in their words, ‘opens up the black-box that is often associated with [machine learning] ML techniques’.
The authors study three types of textual corpora – earnings calls, 10k statements, and Wall Street Journal (WSJ) articles. Their aim is to develop a new set of dictionaries that can measure sentiment in these texts, based on how stock prices react in the days around their release. Put more simply, the idea is to identify a list of words that are relevant to a company’s price action, where relevance is determined by the frequency at which words appear.
Words that appear more frequently will be given positive or negative values (loadings), depending on how stock prices typically respond to them.
This algorithm-based approach to determining whether words should be given positive or negative values is different from the standard technique. For example, the dictionaries from Loughran and McDonald (popular among economic applications) are based on the Harvard-IV dictionaries developed by psychologists. These human-coded ‘bag-of-words’ include 347 positive and 2,345 negative terms.
The authors pit the two approaches against each other. By design, though, the odds are stacked in the algorithm’s favour. General-purpose dictionaries, like LM, were not necessarily designed to choose business-relevant words. The paper’s dictionaries are, so you would expect them to explain more of a firm’s price action. However, it does beg the question of whether we should be using general-purpose dictionaries if context-specific ones can be created…
In total, the authors collect earnings call transcripts from Seeking Alpha on 3,229 firms over 15 years. That makes 85,530 transcripts, with an average of 3,130 words per document. They also collect 76,000 annual reports and 87,000 WSJ texts, with word counts averaging 17,000 and 450, respectively.
The main focus of the paper is on earnings calls, while dictionaries created from annual reports and WSJ articles are used to double-check the findings. The focus on earnings calls is because a firm’s price action is typically far more volatile around this event compared to when annual reports or WSJ texts are released (Chart 1).
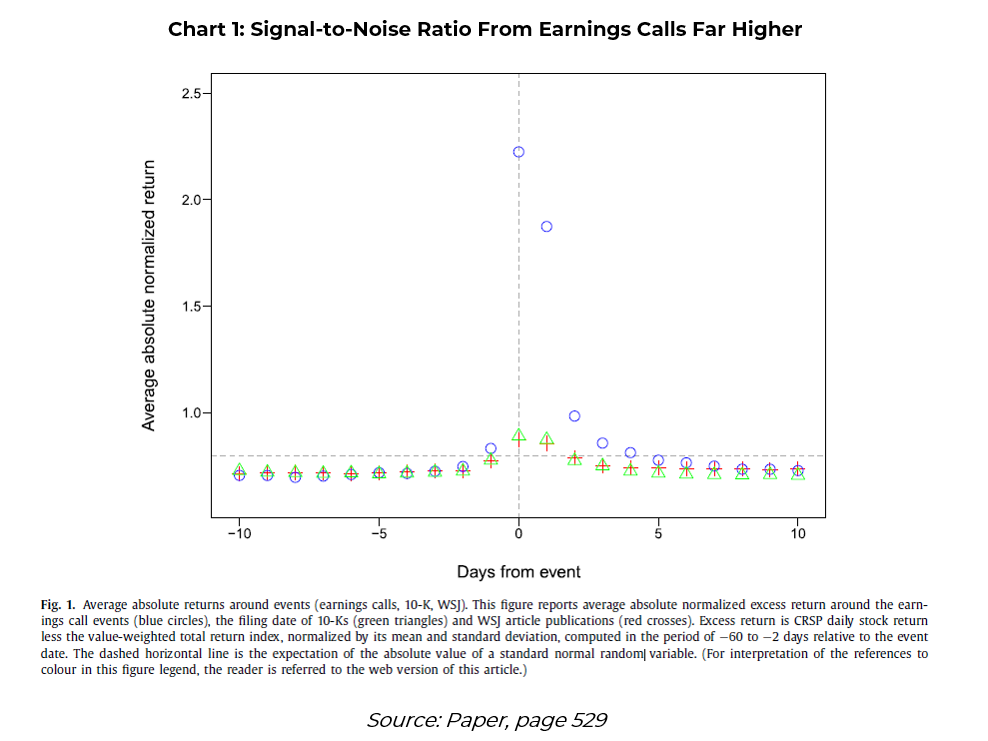
Apart from the texts, the authors also collect firm data from CRSP and Compustat on total returns, size, book-to-market, share turnover, pre-filing period three-factor alpha, and filing period excess returns. All firms must be listed on the NYSE, Amex, or NASDAQ with a stock price of at least $3.
To analyse the texts, the authors use a multinomial inverse regression (MNIR) model. It is similar to a topic model – a popular NLP tool – and involves running regressions of stock price changes on word frequency. These regressions determine whether a word has a positive, neutral, or negative impact on stock prices. A value of one, zero, or minus one is given to words, depending on the regression results.
This way of assigning values to words (one, zero, minus one) allows for a direct comparison to the LM ‘bag-of-words’ approach. Indeed, part of the results involves seeing whether the paper’s machine learning (ML) approach identifies the same words in the dictionary and whether the factor loadings are positive or negative.
To avoid over-fitting, the authors include an extra convolutional layer to their MNIR model, which they label ‘robust MNIR’. They run the regressions over 500 times on a random sub-sample of 5,000 articles to see which frequently used words float to the top and what values the algorithm assigns to them. If a word is positive or negative in more than 80% of the sub-samples, it is included in the final word list.
This stringent criteria leaves just 57 positive and 64 negative words to create the sentiment scores. A sentiment score is created for a given document depending on the ratio of positive and negative words. This score is then added to a standard regression to determine how well it explains a firm’s stock price action over a four-day window around the earnings call.
The setup above was trained on data from 2005 to 2015 and assessed on its out-of-sample performance from 2016 to 2020.
Starting with the sentiment scores derived from the traditional LM dictionaries, a one standard deviation change to the positive (or negative) sentiment score translates into a 0.41% increase (or −0.50% decrease) in the stock price reaction. This result is statistically significant, meaning LM dictionaries can be used to predict stock returns.
However, using the sentiment scores derived only from the new ML dictionaries, the predictability becomes significantly stronger. A one standard deviation change in the positive (negative) sentiment scores results in increases (decreases) in the stock price reaction, amounting to 0.98% (or −1.37%), roughly 2.5 times greater.
Creating sentiment scores from the two combined increases the overall fit of the regression. In other words, it does a better job of explaining variations in stock prices than just creating a sentiment score from one or the other.
Overall, the authors conclude that the robust MNIR algorithm generates sentiment dictionaries that have much stronger contemporaneous correlations with stock returns, relative to the LM dictionaries. They validate that using the K-10 and WSJ articles after.
The authors delve deeper into the words selected for the LM and ML dictionaries, looking for overlapping and contrasting features to explain the differences above.
There are 329 positive LM words, and 57 positive ML words, with just 18 words overlapping. The 329 LM words cover 1.9% of the earnings calls corpus, while the ML words amount to roughly three to four times more.
For negative words, there are 2,315 in the LM dictionary and just 64 in the ML one. Yet, the ML words cover 4.5% of the earnings calls corpus, compared to 1.4% using the LM dictionaries.
The breadth of cover from the ML dictionaries relative to the LM ones shows that the algo-generated ones are more fit for purpose in this context. They elicit stronger signals that provide better predictions. A list of the top 30 positive and negative words is shown below (Table 1).
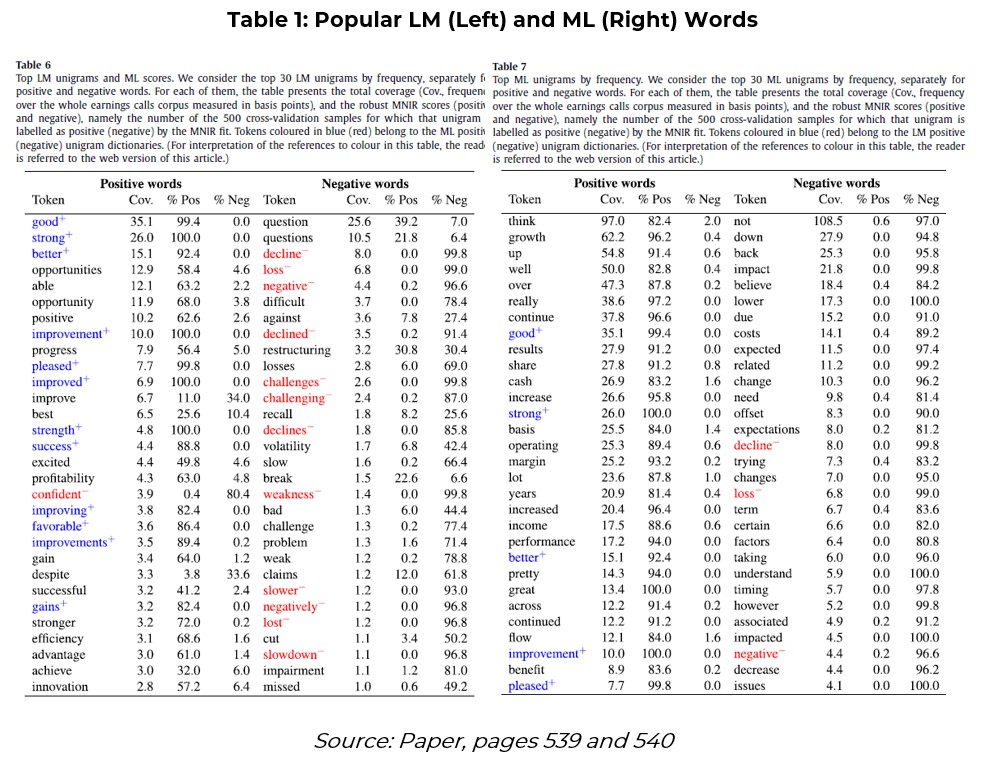
The ML broadly agrees with the LM’s most popular words. For example, ‘good’, ‘better’, and ‘strong’ are both in the ML’s and LM’s top 30 positive words, with ‘strong’ being given a positive value in all 500 samples. Other words like ‘best’ and ‘despite’ are positive words in the LM dictionary, but are not selected by the algorithm. Meanwhile, ‘confident’ actually has a negative influence on stock prices, so is a negative ML word but a positive LM word.
So, while there is broad agreement on the most popular ML and LM words, they do colour words in quite different ways. It seems sensible that ‘best’ is given a positive value in general-purpose dictionaries, but from a business perspective, it is best to stick it in the negative list.
Finally, the authors also create dictionaries from bigrams, which look at the frequencies of multiple words rather than a single one. This is important for keeping some context, which can prove crucial when disambiguating words.
The authors use the colour of bigrams to help understand the sentiment of individual unigrams (Chart 2). The chart shows the percentage of times a given unigram from the LM dictionary is considered positive (blue), negative (red), or neutral (black).
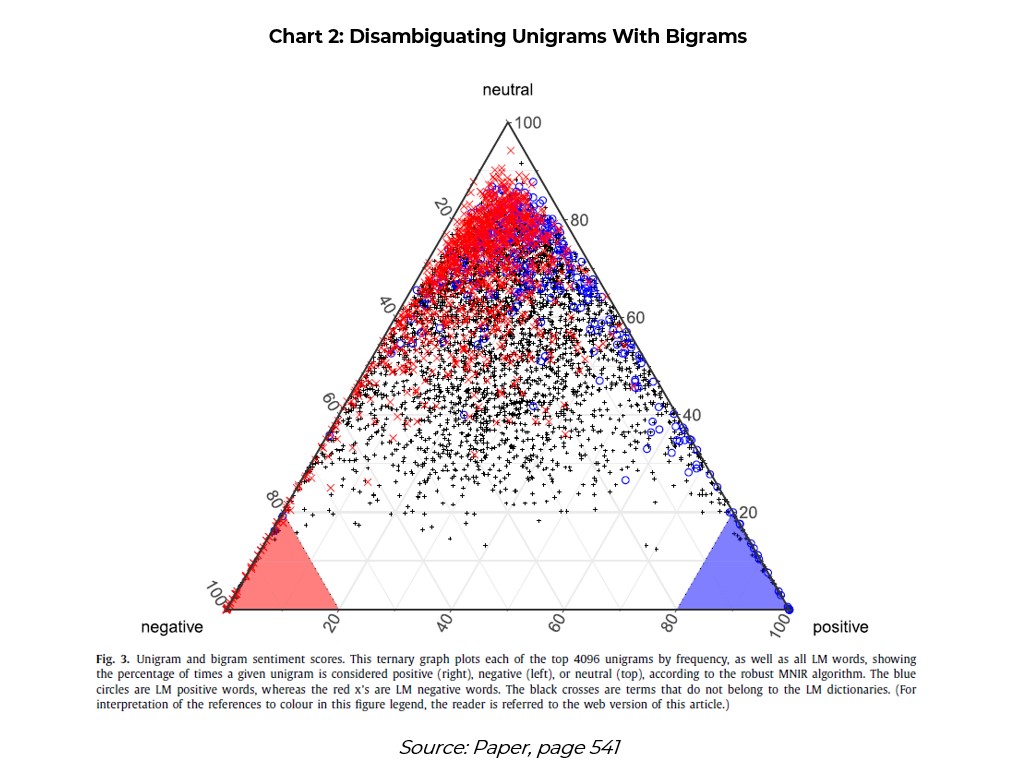
The point of the chart is to show that there is a lot of ambiguity – most words do not sit in the negative or positive corners. So, context is important. According to the authors, the ML algorithm can disambiguate many of these using bigrams.
For example, the positive LM term ‘improve’ does not score very positive in the ML analysis. However, the bigrams ‘continue(s) improve’ and ‘able improve’ get very high scores in the ML analysis. However, ‘improve performance/over/second’ and ‘going/conditions improve’ score negatively.
Using the bigrams in the sentiment score analysis makes the economic magnitude of the coefficients even larger. A one standard deviation change in the positive (or negative) sentiment scores results in increases (or decreases) in the stock price reaction of 1.38% (or −1.36%). The statistical significance is also stronger than with the unigrams.
The paper offers an interesting perspective on whether humans are needed to determine the optimal dictionary for NLP analyses. I suspect there is room for human coders, but algorithm-generated dictionaries can yield economic results for the context in which they are created.
Robust standards need to be added, and arguably a greater level of transparency is needed if we do not rely on humans. Nevertheless, algorithm-generated dictionaries are a good starting point in areas where there are currently no human-coded ones.
For those interested, there is a data depository and code available for this paper.
Spring sale - Prime Membership only £3 for 3 months! Get trade ideas and macro insights now
Your subscription has been successfully canceled.
Discount Applied - Your subscription has now updated with Coupon and from next payment Discount will be applied.