
25 Ways AI Chatbots Are Revolutionising Research

- By Sam van de Schootbrugge
- Sign-up to discuss on Slack
- 7 min read
Every 14 days, ChatGPT produces a volume of text equivalent to all the printed works of humanity. The large language model (LLM) has gained more than 100mn users in its first two months, and its ability to perform cognitive tasks has the potential to revolutionise research in economics and other scientific disciplines. Google and Microsoft will soon be giving their users access to powerful LLMs too.
So how then can we harness the potential of these tools to improve our current workflows as researchers? This is the question a Professor in Economics at the Darden School of Business looks to answers in a new NBER working paper. Anton Korinek ranks ChatGPT’s ability to performs research tasks along six domains: ideation, writing, background research, data analysis, coding, and mathematical derivations.
Providing 25 examples, he shows how LLMs can already help researchers create ideas, improve their writing, translate code between different software platforms, extract data from texts, and produce catchy social media posts. ChatGPT is currently less helpful for tasks that involve mathematics, but Korinek believes that in the long-run LLMs could produce and articulate superior economic models to human economists.
LLMs are a category of foundation models, which are deep learning models. They are pre-trained on data from sources such as Wikipedia, scientific articles, and books in a process called self-supervised learning. This involves the model learning the inherent structure of the training data by predicting parts of the data that are masked.
For instance, an LLM model can be given text fragments with some words hidden and the model learns to predict the missing words. To do this, it must learn syntactic structures, relationships between words and the concepts they represent, the context of sentences and how different words might interact in that context, and so on.
This process involves a lot of computing power and a vast amount of data. The last five years has seen a thousand-fold increase in the computing power of top-end deep learning models. This has enabled LLMs to perform cognitive tasks that can rival a human brain in complexity.
From a textual perspective, models can now form increasingly higher-level abstract representations of concepts and their relationships – they can unscramble words or perform Q&As. In essence, they have developed an internal world model. Based on that world model, the foundation model can be fine-tuned for different applications.
For example, they can be fine-tuned to act as a chatbot (such as ChatGPT) or as system that generates computer code (such as Codex). Examples include DeepMind’s Chinchilla, Google’s PaLM and LaMDA and Anthropic’s Claude.
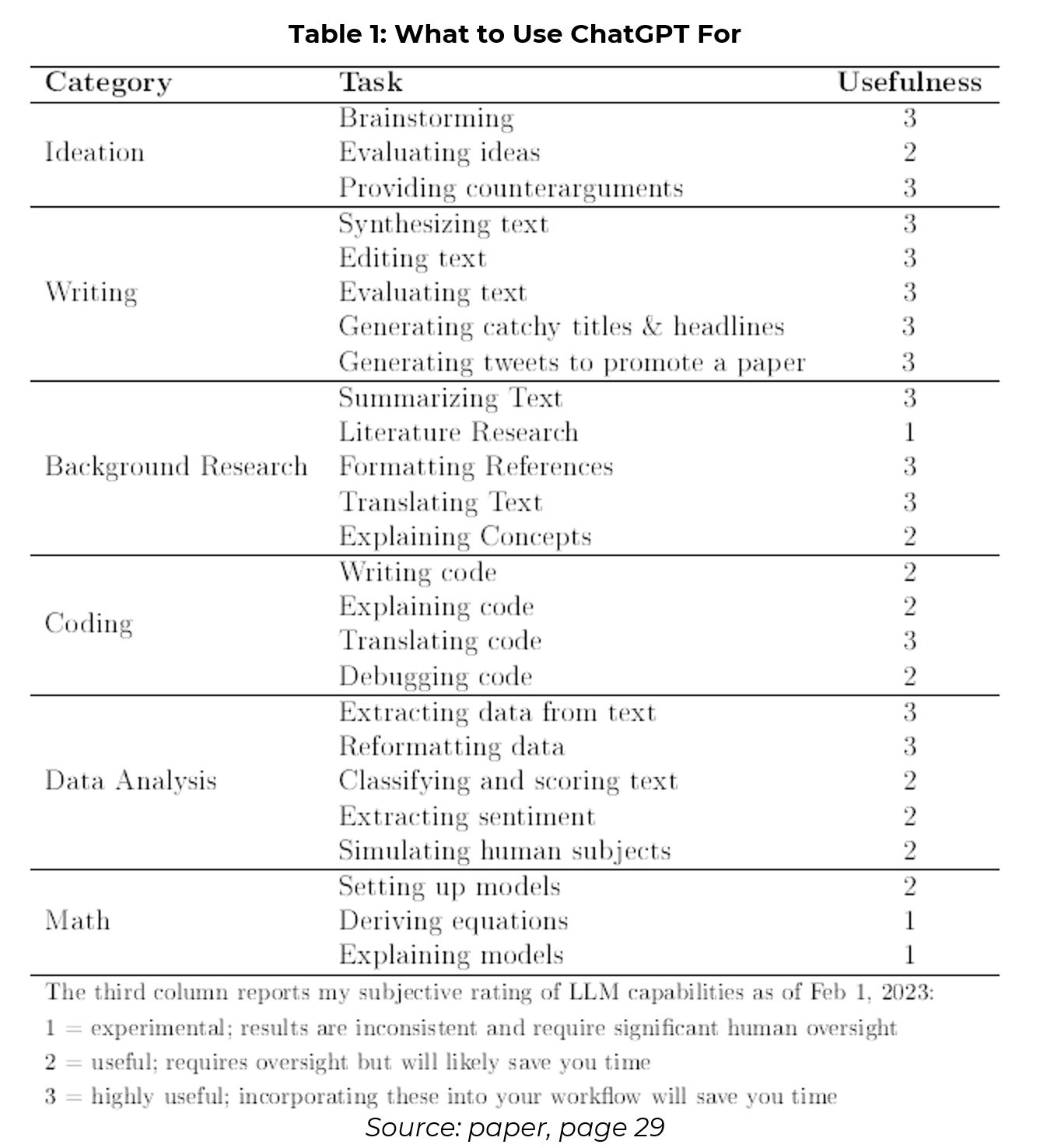
The author demonstrates use cases along six domains: ideation, writing, background research, coding, data analysis, and mathematical derivations. The summary table below scores ChatGPT’s usefulness on each (Table 1).
Coming up with research ideas can be an overwhelming task. ChatGPT may, however, provide just the sounding board you need to structure your thoughts. After all, LLMs are trained on a vast amount of data that represents a cross-section of all human knowledge.
For brainstorming, for example, the author asks ChatGPT to brainstorm the economic channels through which advances in AI may increase inequality (Example 1). The channels listed by the model are not path-breaking, but they are on-topic, largely reasonable, and span a wide range of what I could think of plus some more. Score 3/3.

AI chatbots can also evaluate different ideas, in particular by providing pros and cons of a different research plan (Example 2). As the model’s response suggests, looking at how AI may increase inequality is more useful for positive work, whereas how it may decrease inequality is more useful for normative work. Score 2/3.

Lastly, try asking ChatGPT to provide counterarguments to your hypothesis. In the below example (Example 3), the author felt the AI-generated responses touched on all the important ones he considered, and more. Score 3/3.

The core competence of LLMs is to generate text. This implies that they are quite capable and useful for many tasks related to writing, from synthesising text based on bullet points, changing the style of text, editing text, evaluating styles, and generating titles, headlines, and tweets.
According to the author, LLMs are perhaps best at translating rough bullet points into well-structured sentences. Asking ChatGPT to synthesise text could allow a researcher to concentrate on the ideas in their text rather than the writing process itself. LLMs can even write in a particular way, such as an academic style, LaTeX or even gangster. Score 3/3.
Models can also edit text and explain the corrections it made (Example 4). It can also convert text to be comprehensible to readers of different levels. Try asking it to write a text that is readable for an eight-year-old! Alternatively, you can ask it to make a text incomprehensible, which may also be helpful…Score 3/3

Helpful for me, LLMs can also evaluate text for its style and clarity. For example, the author asks ChatGPT to evaluate the abstract of his paper (Example 5). He agrees with all the shortcomings, and felt the rewritten version did a good job to alleviate them. Score 3/3.

The final two use cases for this section also score 3 out of 3 for helpfulness. That is, asking ChatGPT to come up with catchy titles (as it did for this Deep Dive!) and social media posts. On the latter, it will also come up with good hashtags and will even add a joke if you ask it too.
Only two weeks ago, we put ChatGPT’s summarising skills to the test. Korinek agreed the model can cover all the important bases when summarising texts, especially for shorter passages. However, summaries of larger texts can be overly generalised and repetitive, and require greater manual input. Elicit appears to be a better tool for larger texts. Score 3/3.
For literature reviews, perhaps it is not worth asking LLMs for help. While they have excellent knowledge of different topics, they do not provide citations. And worryingly, if you ask for one, you may get a phantom paper in return…Score 1/3.
On the other hand, ChatGPT could save you a bunch of time formatting references. Put in any reference and ask it to write it into bibtex format – it will generate it perfectly. This is because the LLM will have encountered many references in its training data. Score 3/3.
The author also gives LLMs a perfect three for translating texts, although performance on lower-resource languages for which less digitised text exists is worse. For evaluating concepts, such as regressions or inflation, it can also be helpful. LLMs struggle with more advanced or newer concepts, but for more common topics it can be very helpful. I tried asking it what the central bank policy rate should be using the Taylor Rule…Score 2/3.
A topic that has garnered a lot of attention among my network is ChatGPT’s ability to debug, explain and translate code. GPT3.5 has been trained on large amounts of computer code and is accordingly quite a powerful coder. It is particularly well-versed in Python and R but also quite capable in any common programming language, such as Excel, Stata and Matlab.
On writing code, the author asks ChatGPT to calculate the Fibonacci numbers in Python code (Example 6). The result worked well, and the system can also be told to repeat graphs with different variables or changes in formatting. However, the current capabilities of publicly available LLMs are insufficient to write the full code to simulate most economic problems without human help. Score 2/3.

LLMs can also explain code well (Example 7). Akin to a tutor, it can explain what a line of code means in plain English, which is particularly useful when working with programming languages you are unfamiliar with. Score 2/3.

The author’s highest score in this section goes to translating code. For example, you may wish to translate a code from Python to Matlab. LLMs are very good at doing this for shorter code, while human assistance is still required for longer sequences. Score 3/3.
Lastly, ChatGPT does a good job of debugging code. However, for high-level mistakes such as mistakes in the algorithms underlying the code, human debugging is still required. Score 2/3.
LLMs can format data, extract data from plain text, classify and score text, extract sentiment, and even simulate human test subjects.
The author gives a perfect three out of three score for extracting data from text (Example 8) and reformatting data. On the former, it can extract 10 types of numbers from texts: phone numbers, zip codes, social security numbers, credit card numbers, bank account numbers, dates, times, prices, percentages, measurements (length, weight etc.).

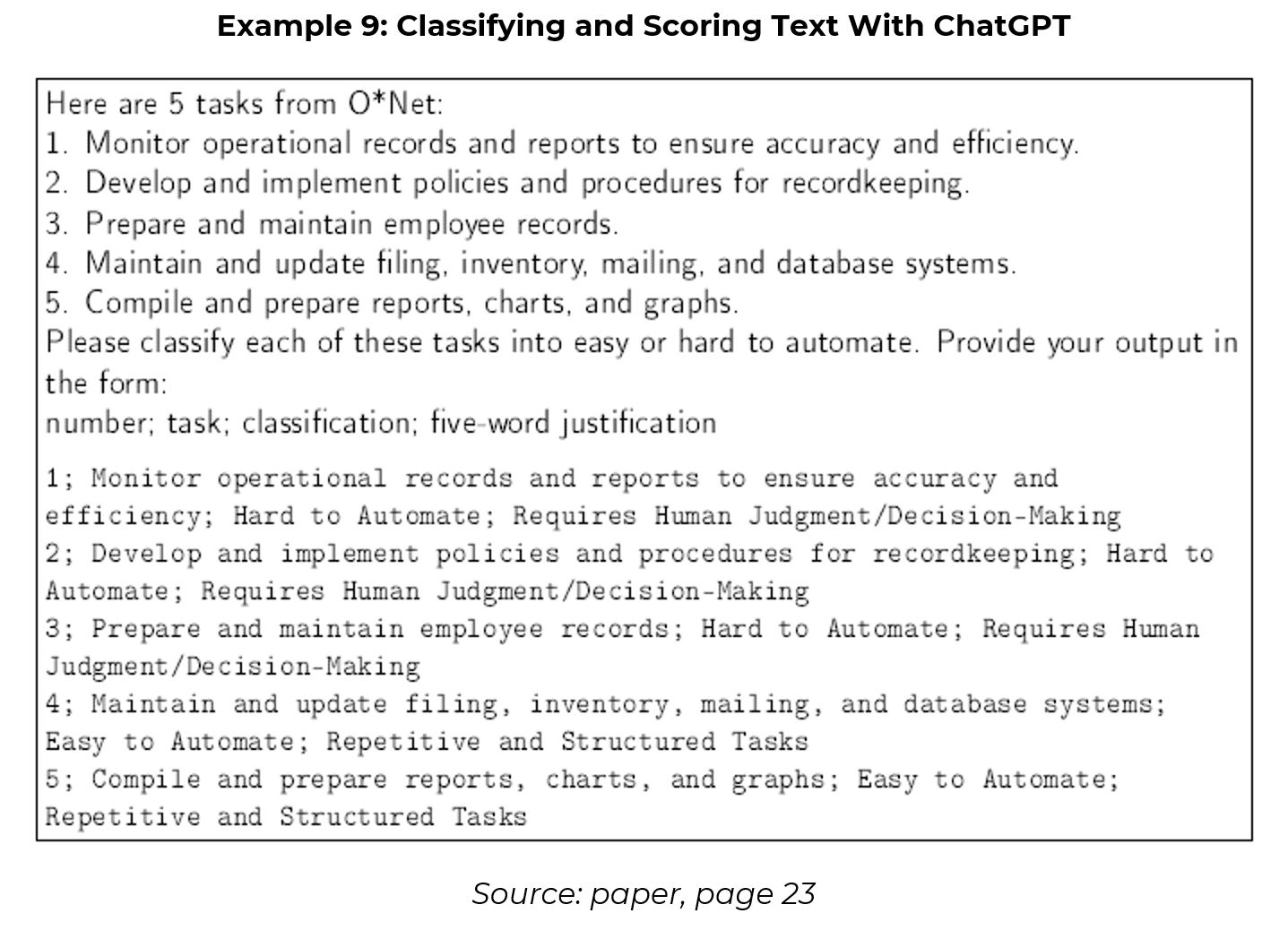
LLMs can also classify and score text (Example 9) because they are increasingly able to understand the meaning of sentences. However, the author notes that, while the results are reasonable, they are not entirely robust, just like a human evaluator. Score 2/3.
Another use case that scored two out of three is extracting sentiment. The author asked ChatGPT to determine whether an FOMC statement was hawkish or dovish (Example 10). While the system’s assessment was correct and well-argued, it was not nuanced enough to determine whether it was more hawkish than the February 2023 statement.

Lastly on this section, the author looks at the model’s ability to simulate human subjects. GPT3 is conditioned on the socio-demographic backstories of real humans and demonstrate that subsequent answers to survey questions are highly correlated with the actual responses of humans with the described backgrounds, in a nuanced and multifaceted manner. This is put to the test (Example 11).

If used correctly, such examples can provide useful insights about our society. However, there is also significant risk that the simulated results simply propagate false stereotypes. Score 2/3.
I will keep this section short. LLM’s ability to perform mathematical derivations is emerging but still weak. It is estimated that ChatGPT’s mathematical abilities are significantly below those of an average mathematics graduate student. The author therefore scores ChatGPT’s ability to handle mathematical tasks the lowest.
In the short- to medium-term, the author believes LLMs can become useful assistants that can be integrated into researcher workflows. They are good for micro tasks that would be too inefficient to ask a human assistant.
However, just like human assistants, AI research assistants may also one day become researchers of their own. Korinek believes that in the long-term LLMs will be like the chess computer, DeepMind, eventually producing superior economic models.
At this point though, human researchers, especially when AI-assisted, are still the best technology around for generating economic research!
The author mentions a few important points when dealing with ChatGPT:
On the final point, he is keen to stress the limitations of ChatGPT. Current LLMs can produce text that sounds highly authoritative, even when it is completely wrong. Their primary objective is to generate content – humans must still evaluate it.
That said, he also warns about underestimating LLMs capabilities. A former Chairman for Mensa International reports that ChatGPT has a tested IQ of 147 (99.9th percentile) on a verbal-linguistic IQ test. LLMs are also advancing quickly, so they are likely to have a disruptive impact at some stage.
Spring sale - Prime Membership only £3 for 3 months! Get trade ideas and macro insights now
Your subscription has been successfully canceled.
Discount Applied - Your subscription has now updated with Coupon and from next payment Discount will be applied.